|
I am currently a Ph.D. student under the supervision of Prof. Dan Xu, at Hong Kong University of Science and Technology (HKUST). I received my Bachelor's Degree and Master's Degree from Shanghai Jiao Tong University (SJTU) in 2021 and 2024, advised by Prof. Jie Yang and Prof. Wei Liu. My primary research interests lie in 3D vision. My past research experience includes vision-language pretraining, depth estimation, and 3D/4D Gaussian Splatting. Currently, I am particularly interested in 3D/4D reconstruction, spatial intelligence, and world models. Feel free to contact me if you are interested in collaborating on these topics. Email1 / Email2 / Google Scholar / Github |

|
|
|
|
|
|
|
|
Jinfeng Liu, Lingtong Kong, Mi Zhou, Jinwei Chen, Dan Xu ICLR, 2026 project page / arxiv / code HDR dynamic scene reconstruction from alternating-exposure monocular videos with 4D Gaussian splatting for spatiotemporal novel view synthesis. |
|
|
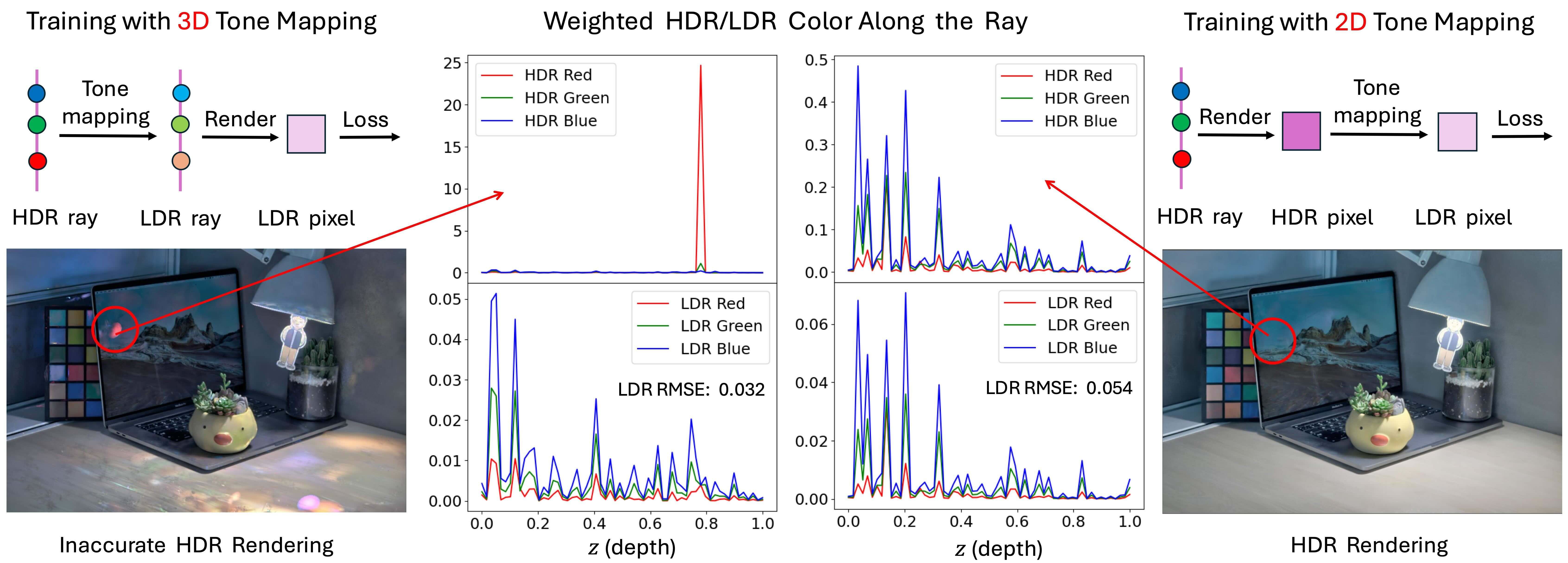
Jinfeng Liu, Lingtong Kong, Bo Li, Dan Xu CVPR, 2025 project page / arxiv / code Unified 3D and 2D local tone mapping in Gaussian splatting for HDR novel view synthesis with uncertainty-guided fusion of dual LDR renderings. |
|
|
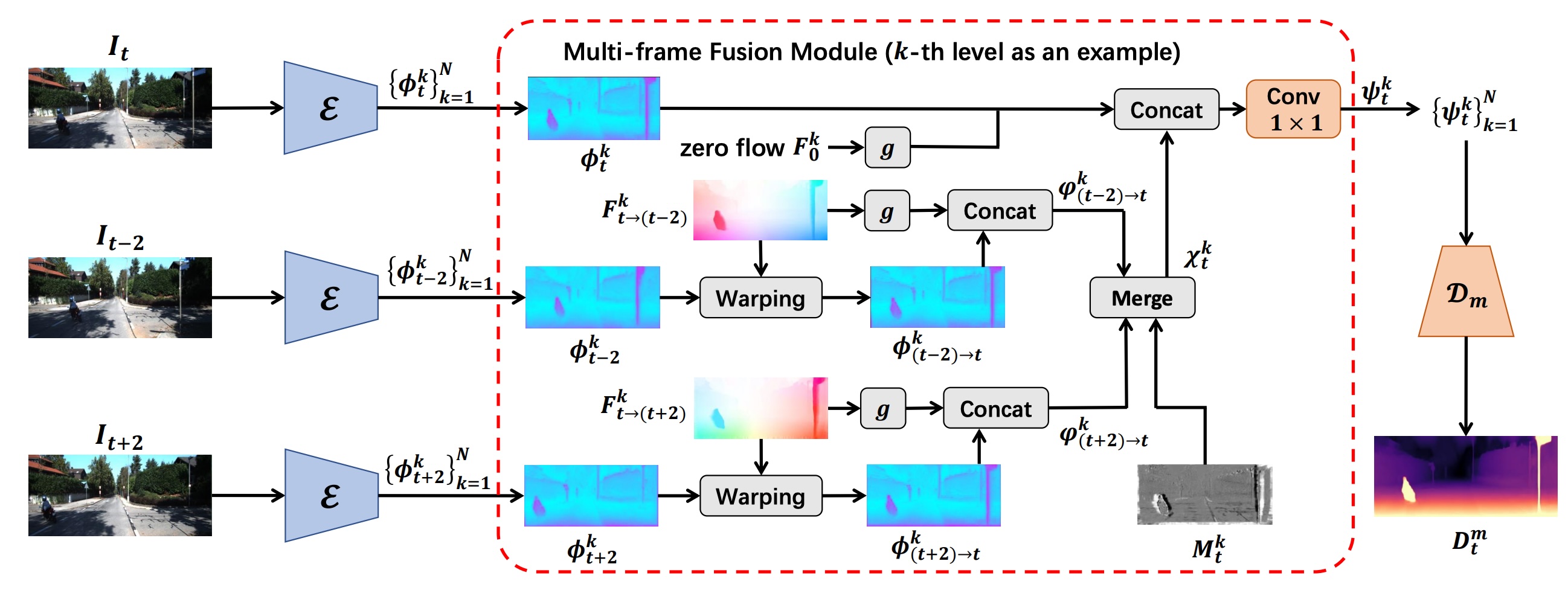
Jinfeng Liu, Lingtong Kong, Bo Li, Zerong Wang, Hong Gu, Jinwei Chen ECCV, 2024 arxiv / code A unified self-supervised framework for single- and multi-frame monocular depth estimation via video frame interpolation. |
|
|
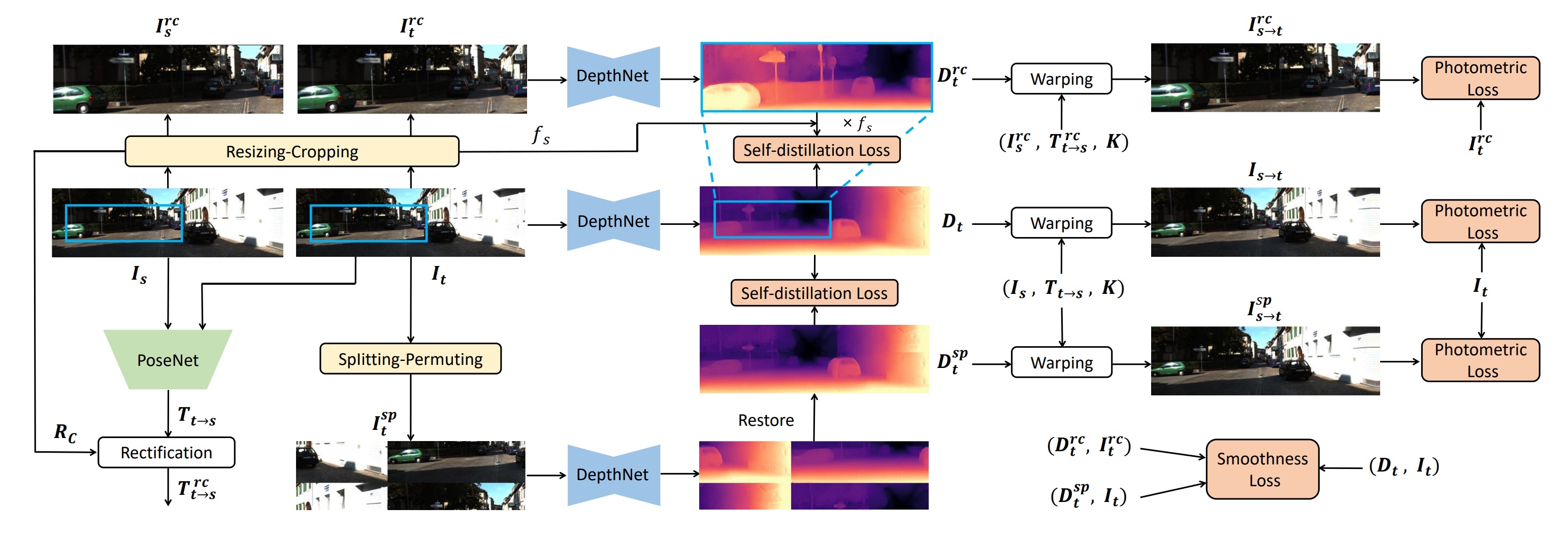
Jinfeng Liu, Lingtong Kong, Jie Yang, Wei Liu IEEE RA-L, 2024 arxiv / code Improved self-supervised monocular depth estimation with resizing-cropping and splitting-permuting data augmentations. |
|
|
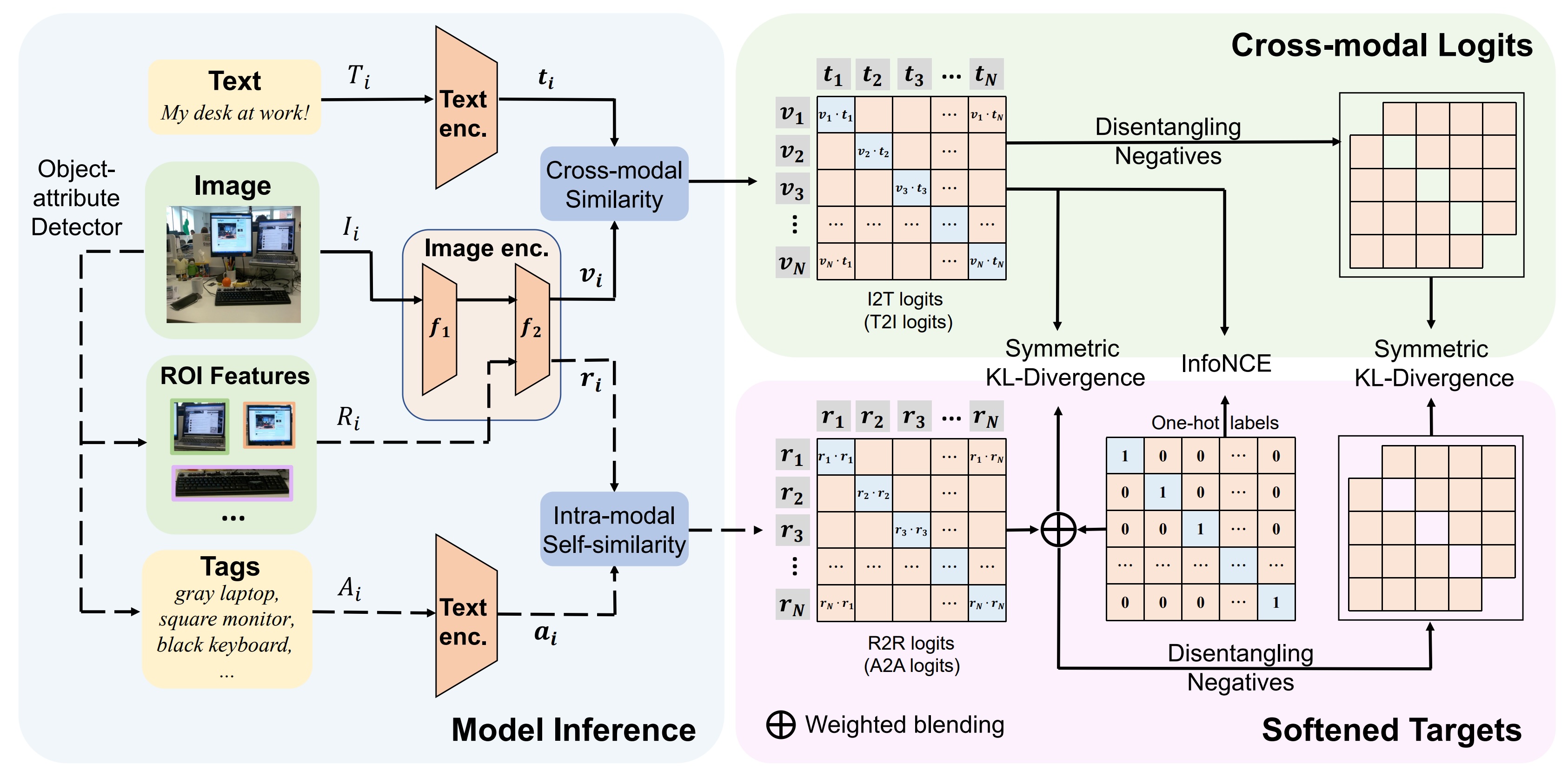
Yuting Gao*, Jinfeng Liu*, Zihan Xu*, Tong Wu, Enwei Zhang, Wei Liu, Jie Yang, Ke Li, Xing Sun (* equal contribution) AAAI, 2024 arxiv Softer cross-modal alignment for CLIP using softened targets derived from intra-modal self-similarity. |
|
|
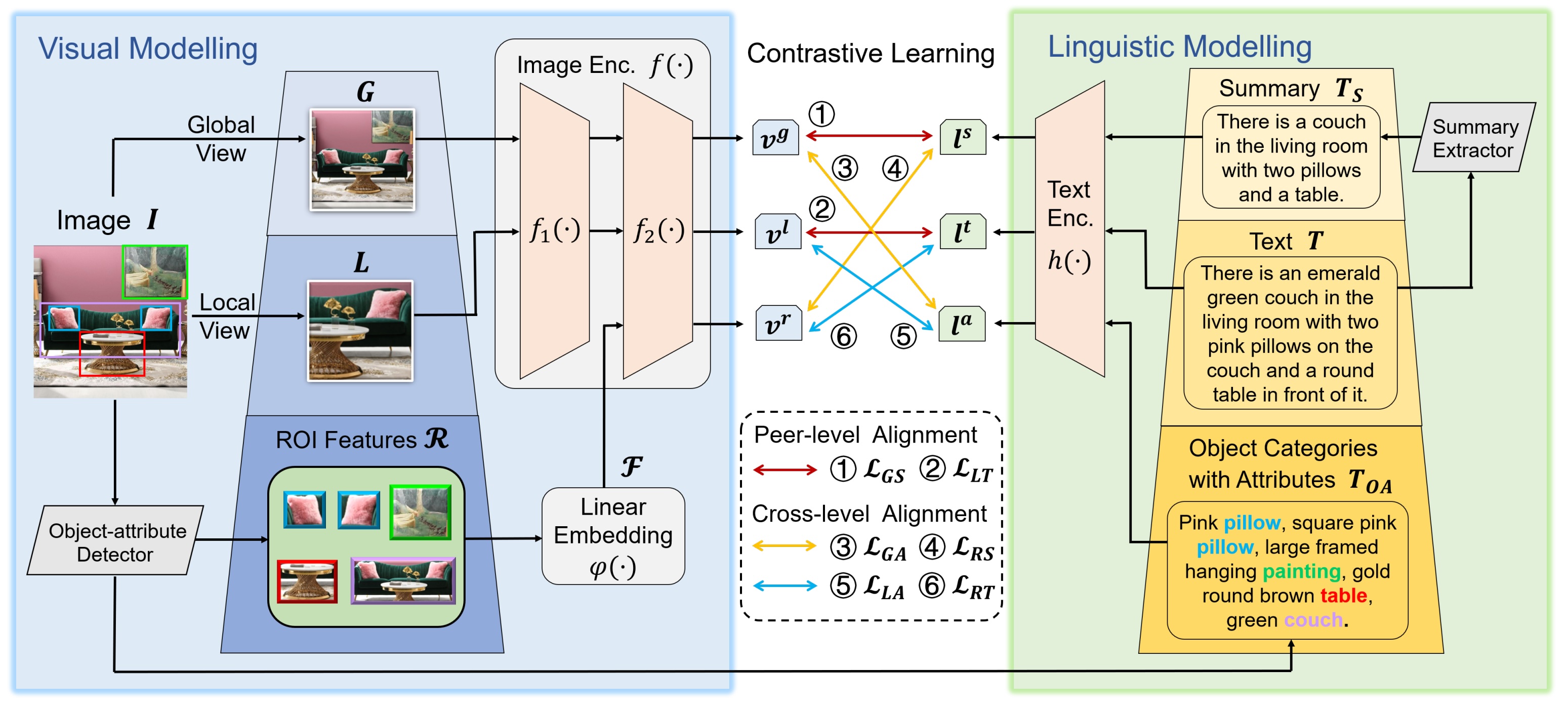
Yuting Gao*, Jinfeng Liu*, Zihan Xu*, Jun Zhang, Ke Li, Rongrong Ji, Chunhua Shen (* equal contribution) NeurIPS, 2022 (Oral) arxiv / code Hierarchical image-text alignment via peer-level and cross-level feature alignment for improved CLIP data efficiency and zero-shot performance. |

|
|
|
|